When Browser Harnesses Help, and When They Hurt
Keon Kim and Krish Chelikavada

Jina MCP topped WebVoyager and AssistantBench, but the more important lesson is about model-interface design.
Browser harnesses are compression layers.
They compress what the model sees, what actions it can take, how much browser history it has to carry, where local recovery happens, and how success is checked. That compression can help or hurt.
A harness helps when it removes burden the model cannot handle. A harness hurts when it removes information the model could have used.
That is the core idea behind capacity-matched compression. Web-agent performance depends on the match among planner capacity, actor reliability, compression level, task complexity, and verification strength.
The Core Finding
We tested specialized browser harnessing across models with different capacities.
The test used sampled tasks from WebArena-Verified-derived task pools. We concatenated verified subtasks into longer compound tasks across GitLab, Reddit/Postmill, and shopping_admin to increase task complexity and stress long-horizon browser execution.
The pattern flipped.
| Model | Raw control | Macro-action harness | Change |
|---|---|---|---|
| Opus | 50% | 20% | -30 pp |
| Haiku | 35% | 55% | +20 pp |
Observation was held fixed. The main change was the action interface. Raw control exposed primitive browser actions. Macro-action compression exposed higher-level browser operations.
The same compression hurt Opus and helped Haiku.
Haiku improved because the harness reduced the amount of browser mechanics it had to reason through. It had less context, action history, grounding, and recovery to manage.
Opus got worse because it could already use the raw browser state. The harness removed useful detail and control.
The pattern became larger when action compression was bundled with structured observation compression.
| Model | Raw control | Bundled compression | Change |
|---|---|---|---|
| Opus | 50% | 25% | -25 pp |
| Haiku | 35% | 75% | +40 pp |
The claim is not that more compression is always better.
The claim is that compression has to match the model and the task.
The benchmark wins show the system works. The ablations suggest why the harness helps some models and hurts others.
What the Harness Compresses
A browsing agent does not act on the web directly. It acts through an interface.
That interface determines the planner-visible world.
A specialized browser harness compresses three things.
1. Observation
The model sees a smaller representation of browser state instead of raw screenshots, DOM, accessibility trees, CDP output, or full execution traces.
2. Action
The model chooses higher-level operations instead of individual clicks, waits, scrolls, selector calls, retries, and extraction steps.
3. Recovery
The harness handles modals, stale selectors, dynamic content, timing issues, scrolling, extraction failures, and local verification.
This can make a hard browser task much smaller for a weaker model. It can also destroy information that a stronger model would have used.
For example, a harness might summarize a page as "checkout form is visible." That may be enough for a small model. Raw CDP might show that the shipping field is disabled until a country dropdown fires a JavaScript event. A stronger model may use that raw state to recover. The harness summary erased the recoverable detail.
The right question is how much compression the planner can tolerate for the task distribution.
A harness has two opposing effects.
It helps by removing work from the planner. It hurts by hiding information from the planner.
So the question is simple.
Does the harness remove more burden than the information it destroys?
A practical model is:
harness value =
saved planner effort
+ actor execution benefit
- information lossThe harness helps when:
saved planner effort + actor execution benefit > information lossThe tradeoff is relative to both model capacity and task complexity.
For a weak model, even moderately complex browser tasks can exceed usable capacity, so reducing planner burden creates large gains.
For a strong model, simple or moderate tasks may already fit within capacity, so compression adds less value and information loss can dominate.
As task complexity increases, even strong models can become capacity-constrained again. In that regime, harnessing can help frontier models too, as long as the actor preserves the information needed for planning and verification.
The actual variable is the ratio between task complexity and model capacity.
High ratio means compression helps.
Low ratio means compression can hurt.
Why Weaker Models Benefit
Weak models fail under raw browser control for reasons that are not purely about reasoning.
They suffer from context rot.
Context rot is what happens when the planner's context fills with stale observations, failed actions, partial recoveries, irrelevant page details, old browser state, and execution debris. The context window is technically larger, but the useful signal gets buried.
As the browser trace grows, the planner has to carry failed clicks, retries, intermediate page states, irrelevant DOM fragments, old screenshots, and recovery attempts. The original user goal gets harder to recover.
The model may still have the tokens in context, but the useful signal becomes harder to use.
It starts over-weighting the latest browser state. It loses track of the original objective. It makes brittle grounding decisions. It repeats failed paths. It stops too early or keeps acting after the useful path is gone.
A harness reduces context rot by moving low-level execution out of the planner's context.
Instead of forcing the planner to reason through every click, scroll, wait, retry, and failed selector, the harness exposes semantic operations.
For Jina MCP, the production interface is compact.
act(instruction) execute a browser operation or local interaction sequence
get(query) extract information from the current page or nearby pages
check(condition) verify whether a state or fact appears trueThe planner sends intent. The actor handles browser execution and returns only task-relevant feedback.
For Haiku-like models, this is capacity amplification. The task becomes small enough to solve.
That is why specialized harnessing can look like a capability jump.
It is burden removal and context-rot reduction.
Why Stronger Models Can Be Obstructed
Frontier models are increasingly able to use raw browser state directly.
Opus 4.7 can often inspect messy CDP output, infer page structure, reason over intermediate browser state, and recover from low-level failures.
For models at that level, a harness can become a lossy bottleneck.
The actor may summarize away uncertainty. It may choose the wrong evidence. It may hide a failed local step behind a confident report. It may remove information that the planner could have used for recovery. It may narrow the action space too early.
This is the inversion.
The same abstraction that helps Haiku can hurt Opus on tasks already within Opus's usable capacity.
A strong planner does not always want raw control. If the task is complex enough, actor advantage is large, and information loss is low, compression still helps. But the optimal compression level should generally decrease as planner capacity increases for a fixed task distribution.
Where Harnesses Create Value
A browser harness is best understood as a capacity-matched execution layer.
It expands the cost-performance frontier by deciding what belongs in the planner and what belongs in the browser actor.
The expensive planner should spend tokens on task decomposition, evidence integration, ambiguity resolution, and stopping decisions.
The cheaper actor should handle browser mechanics, extraction, scrolling, waits, retries, local checks, and traceable execution.
In Jina MCP, we did not optimize for maximum abstraction. We optimized for the right amount of abstraction for the benchmark task distribution.
The benchmarked tasks were complex enough that raw browser control wasted high-tier model capacity on repetitive browser mechanics, but still compact enough that the planner did not need every low-level browser detail. Matching compression to that regime let us preserve near high-tier native performance while pushing much of the execution into a cheaper actor model.
That gives harnesses three sources of value.
Capacity amplification
Weaker planners can solve browser tasks that raw control makes too large.
Cost optimization
Expensive model tokens stay focused on planning, while cheaper actor tokens handle repetitive browser work.
UX and operations
Human interaction is usually the bottleneck. A well-designed harness shapes how people steer, inspect, and correct the agent in flight through cleaner traces, replay, observability, evaluation, and human override.
The first source is the most visible in benchmarks.
The second and third are more durable.
Benchmark Results
This same system class topped two public browsing-agent benchmarks.
On WebVoyager, Jina MCP + Claude Code + Opus 4.7 + GPT 5.4 Nano reached 98.9%, passing 603 of 610 real-website tasks. The run ranked first on Apr 21, 2026.
The run took 48h 24m, used 46.7M tokens, averaged 97K tokens per task, and averaged 15.6 browser steps per task. It was judged by GPT-5 against up to 15 screenshots per task. A handful of expired March 2026 date anchors were minimally adjusted to 2026 or 2027 so the agent could complete them after March 2026.
On AssistantBench, Jina MCP reached 42.10% accuracy with a 100% answer rate using Claude Opus 4.7 with GPT-5.4 Nano inside the actor.
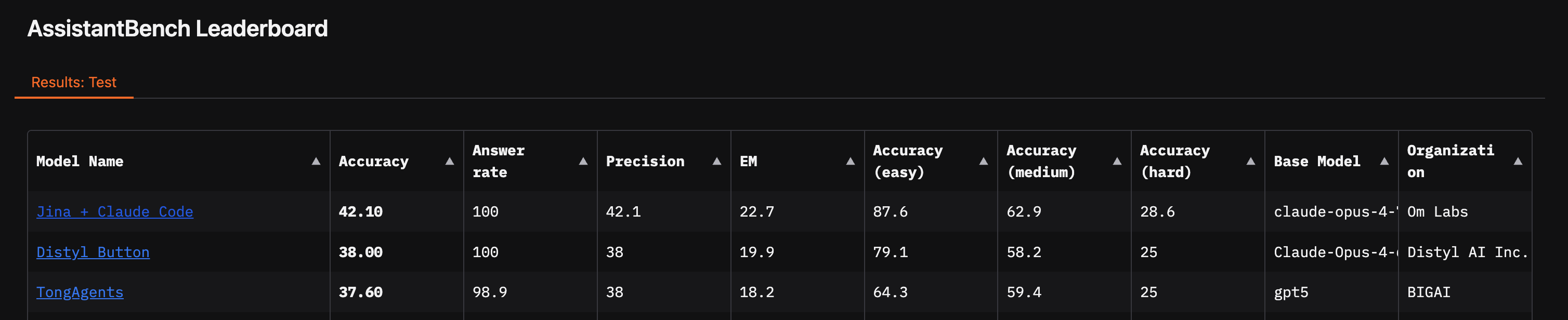
These results matter because WebVoyager stresses live website browsing, while AssistantBench stresses longer web research across many sites.
They show that the planner-actor architecture is practically competitive.
They do not mean maximum compression is best. The system worked because the interface matched the benchmark task distribution.
The Harness Lesson
This looks like the Bitter Lesson showing up at the agent-interface layer.
Specialized structure helps before general models catch up. Then general models absorb the specialization.
Machine translation moved from rules, phrase tables, and language-specific systems to general neural translation.
Summarization moved from extraction heuristics and sentence-ranking pipelines to general instruction-following models.
Coding moved from autocomplete, templates, snippets, and narrow IDE workflows to general code models that can refactor, debug, translate languages, write tests, and edit across files.
Browser agents are following the same pattern.
A harness creates alpha while models still struggle with long traces, messy browser state, dynamic UI, grounding, and recovery. But if the advantage is only hiding browser complexity from the model, frontier models will absorb it.
Browser harnesses will not disappear. Their pure capability advantage will decay. Their operational advantage can compound.
Early harness specialization improves capability.
Later harness specialization improves cost, latency, reliability, observability, workflow integration, auditability, and UX.
The moat shifts from "we made the model smarter by wrapping it" to "we operate the system better than anyone else."
What This Means for Agent Builders
Do not design one interface for every model.
For weaker planners, compress aggressively. Hide browser mechanics. Expose semantic operations. Keep context short. Move recovery into the actor.
For frontier planners, preserve raw evidence. Give the model inspection tools. Avoid summaries that destroy recoverable state. Let the model decide when it needs detail.
The design rule is simple.
Use compression when the planner is capacity-constrained relative to the task.
Use raw detail when the planner can exploit it.
Use verification when state matters.
This also shapes the moat.
Specialized harnesses create alpha where model capacity has not caught up to the task distribution. That is exploitable now, but the technical moat from harness specialization alone will decay. As frontier models improve, more workflows move from larger than model capacity to within model capacity.
When that happens, the same harness can shift from advantage to bottleneck.
If the only advantage is hiding browser complexity from the model, frontier models will eat it.
If the advantage is routing, verification, replay, cost control, latency control, auditability, workflow integration, and product UX, model improvements make the system more valuable.
The harness is the wedge.
The system is the product.
Read More
References
- Akkil, D., Allaham, M., Raj, A., Abuelsaad, T., and Kokku, R. 2026. Emergence WebVoyager: Toward Consistent and Transparent Evaluation of Web Agents in the Wild. arXiv:2603.29020.
- He, H., Yao, W., Ma, K., Yu, W., Dai, Y., Zhang, H., Lan, Z., and Yu, D. 2024. WebVoyager: Building an End-to-End Web Agent with Large Multimodal Models. ACL 2024. arXiv:2401.13919.
- Sutton, R. 2019. The Bitter Lesson.
- Yang, K., Liu, Y., Chaudhary, S., Fakoor, R., Chaudhari, P., Karypis, G., and Rangwala, H. 2024. AgentOccam: A Simple Yet Strong Baseline for LLM-Based Web Agents. arXiv:2410.13825.
- Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K., and Cao, Y. 2022. ReAct: Synergizing Reasoning and Acting in Language Models. ICLR 2023. arXiv:2210.03629.
- Yoran, O., Amouyal, S. J., Malaviya, C., Bogin, B., Press, O., and Berant, J. 2024. AssistantBench: Can Web Agents Solve Realistic and Time-Consuming Tasks?. arXiv:2407.15711.
- Zheng, B., Gou, B., Kil, J., Sun, H., and Su, Y. 2024. SeeAct: GPT-4V(ision) Is a Generalist Web Agent, If Grounded. ICML 2024. arXiv:2401.01614.
- Zhou, S., Xu, F. F., Zhu, H., Zhou, X., Lo, R., Sridhar, A., Cheng, X., Ou, T., Bisk, Y., Fried, D., Alon, U., and Neubig, G. 2023. WebArena: A Realistic Web Environment for Building Autonomous Agents. ICLR 2024. arXiv:2307.13854.